기술 인사이트
AI용 데이터 스토리지에서의 CMX(Context Memory eXtension) 이해
NVIDIA CMX(Context Memory Storage)가 무엇인지, 어떻게 작동하는지, 스토리지를 위한 포드 수준 컨텍스트 계층으로 작동하여 AI 워크로드를 어떻게 개선하는지 알아보십시오.
April 28, 2026
더 읽기
기술 인사이트
NVIDIA CMX(Context Memory Storage)가 무엇인지, 어떻게 작동하는지, 스토리지를 위한 포드 수준 컨텍스트 계층으로 작동하여 AI 워크로드를 어떻게 개선하는지 알아보십시오.
April 28, 2026
더 읽기
산업 솔루션
AI 워크로드에서 KV 캐시에 대한 스토리지 과제를 해결하기 위해 CSAL과 Bluefield-3 DPU의 통합을 살펴보십시오.
April 22, 2026
더 읽기
고객 평가
Solidigm SSD를 사용하여 가장 가혹한 환경에서 HPC와 액체 냉각을 에지로 가져가는 DUG Technology의 방법을 알아보십시오.
April 12, 2026
더 읽기
기술 인사이트
데이터 센터용 액체 냉각 설명: 방법, 이점, 하이브리드 대 공랭, 고밀도 AI 지원 엔터프라이즈 인프라를 지원하는 수냉식 SSD.
April 6, 2026
더 읽기
기술 인사이트
Ace Stryker는 NVIDIA GTC ’26에서 가장 핵심적인 사항으로 데이터 스토리지가 AI 워크로드를 확장하는 데에 중심적인 역할을 한다는 점을 강조합니다.
March 30, 2026
더 읽기
고객 사례
CoreWeave의 Jacob Yundt는 액체 냉각이 어떻게 매우 밀도가 높은 랙에서 더 많은 컴퓨팅을 위해 전력과 공간을 확보하는지 설명합니다. AI용 클라우드가 점점 더 뜨거워지고 밀도가 높아짐에 따라 CoreWeave는 수냉식 스토리지를 위해 Solidigm에 의존합니다.
March 24, 2026
더 읽기
산업 솔루션
NVIDIA GTC 2026에서 Solidigm이 발표한 포스터의 세부 정보를 확인하시기 바랍니다. 이 포스터는 BlueField-3 및 Solidigm CSAL 소프트웨어로 구동되는 솔루션을 소개하여 우수한 처리량, CPU 오버헤드 감소, 강력한 데이터 보호를 제공합니다.
March 15, 2026
더 읽기
고객 평가
PEAK:AIO의 Roger Cummings가 솔리다임 고용량 SSD가 에지에서 AI 교육 및 추론을 위한 속도, 성능 및 사용 편의성을 제공하는 방법을 보여드립니다.
March 3, 2026
더 읽기
산업 솔루션
AIC와 Solidigm이 AI, HPC 및 분리형 스토리지 컴퓨팅 환경을 위한 확장 가능한 고성능 스토리지 솔루션을 어떻게 지원하는지 알아보십시오.
February 23, 2026
더 읽기
VAST Data와 솔리다임은 AI 데이터가 스토리지 계층화를 요구함에 따라, HDD를 고밀도의 효율적인 스토리지로 대체하여 데이터의 성능을 극대화합니다.
February 3, 2026
더 읽기
기술 인사이트
NVIDIA의 ICMSP가 플래시 스토리지를 컨텍스트 계층으로 사용하여 추론 메모리를 GPU 근처의 재사용 가능한 공유 리소스로 관리하여 성능과 확장성을 개선하는 방법을 알아보세요.
January 27, 2026
더 읽기
산업 솔루션
Solidigm 팀원들이 SSD 혁신 강화에서부터 내부 역량 강화를 위한 일일 업무 간소화에 이르기까지 실제 상황에 맞는 AI 솔루션을 개발하는 방법에 대해 알아보세요.
January 13, 2026
더 읽기
산업 솔루션
DPU 기반 분산형 유연 스토리지에 대한 이 상세한 분석에서 Solidigm SSD와 CSAL이 고성능, 고용량 아카이브 스토리지의 새로운 시대를 여는 방법에 대해 알아보세요.
December 30, 2025
더 읽기
고객 사례
Dell과 NVIDIA OVX가 PowerEdge 서버와 PowerScale 스토리지를 고성능 Solidigm NVMe SSD와 결합하여 차세대 미디어 제작을 지원하는 방법을 알아보세요.
December 16, 2025
더 읽기
기술 인사이트
조직이 데이터를 원본에 가까운 곳에서 처리하고자 함에 따라 엣지 데이터 스토리지가 어떻게 진화하는지 알아보세요.
December 2, 2025
더 읽기
기술 인사이트
칩 직접 접촉(direct-to-chip) 냉각 방식을 적용한 최초의 완전 액체 냉각 SSD가 AI 데이터 센터를 획기적으로 변화시키는 방법을 알아보세요.
November 18, 2025
더 읽기
기술 인사이트
용량, 성능, 에너지 소비, 신뢰성과 같은 기술적 특성이 자기 테이프에서 HDD, 그리고 현재의 플래시 기반 SSD로 데이터 스토리지의 발전에 어떤 영향을 끼쳤는지 알아보십시오.
November 4, 2025
더 읽기
기술 인사이트
AI 워크로드에 대한 성능 분석 결과를 얻으려면 두 개의 서버 플랫폼에서 MLPerf 벤치마크 모음집을 사용하여 Solidigm SSD에 대한 자세한 개요를 참조하세요.
October 14, 2025
더 읽기
기술 인사이트
Solidigm AI Central Lab은 스토리지와 최첨단 연구를 위한 AI 기능을 결합하여 AI 학습과 추론을 지원합니다.
September 30, 2025
더 읽기
산업 솔루션
Solidigm의 첨단 SSD 기술과 결합된 VergeIO의 초융합 인프라(UCI) 플랫폼은 컴퓨팅, 스토리지 및 네트워킹을 하나의 효율적인 환경으로 통합합니다.
September 16, 2025
더 읽기
기술 인사이트
본 백서에서는 AI 배포 시 스토리지 장치로 확장된 액체 냉각이 열 효율성을 높여 운영 비용을 절감할 수 있는 기회를 어떻게 제공하는지 알아봅니다.
September 9, 2025
더 읽기
기술 인사이트
CPU 병목 현상을 제거하고, GPU 워크로드 효율성을 유지하고, 아키텍처를 활용하여 가속 성능 저하 없이 확장 가능하고 비용 효율적인 AI 인프라를 구축하는 방법에 대해 알아보세요.
September 2, 2025
더 읽기
산업 솔루션
DUG, Hypertec 및 Solidigm이 가장 혹독한 환경의 에지에 구축하기 위한 모바일 데이터 센터에서 어떻게 협업했는지 알아보십시오.
August 26, 2025
더 읽기
기술 인사이트
Solidigm이 스토리지를 에지로 확장하여 혁신적인 기술을 지원하기 위해 어떻게 다양한 산업 분야의 기업들과 협력하고 있는지 알아보십시오.
August 11, 2025
더 읽기
산업 솔루션
Solidigm이 슬롯당 더 많은 테라바이트, GPU 메모리로의 더 빠른 파이프, 변화하는 워크로드에 적응하는 더 스마트한 계층화를 통해 에지 스토리지를 지원하는 방법을 알아보세요.
August 7, 2025
더 읽기
기술 인사이트
RAG(검색 증강 생성) 기술이 Solidigm 및 Metrum AI의 SSD 오프로딩 기술을 이용하여 기업의 비즈니스 문제를 어떻게 해결하는지 알아보십시오.
July 29, 2025
더 읽기
산업 솔루션
기존 HDD에서 올플래시 QLC SSD로 전환하면 10년 동안 TCO를 상당히 절감할 수 있습니다. 자세한 내용을 알아보려면 이 비용 비교 백서를 자세히 살펴보십시오.
July 22, 2025
더 읽기
산업 솔루션
Solidigm의 고밀도 QLC 드라이브와 Xinnor의 xiRAID가 RAID 재구축 상황에서 어떻게 안정성과 성능을 높이는지 알아보세요
July 15, 2025
더 읽기
산업 솔루션
비용, 시스템 공간 및 에너지 소비를 어떻게 줄일 수 있습니까? AI 및 컴퓨팅 집약적 데이터 워크로드의 경우, Ocient와 Solidigm이 해결책을 제공할 수 있습니다. 방법 보기.
July 1, 2025
더 읽기
산업 솔루션
Solidigm과 UBIX가 CSAL을 활용해 어떻게 AI 스토리지 솔루션 혁신을 추진하고 전력과 공간을 절약하고 있는지 알아보십시오.
June 26, 2025
더 읽기
기술 인사이트
데이터와 스토리지로 더 살기 좋은 세상을 만드는 방법을 탐색하는 가운데, 데이터의 가치, 데이터를 처리하여 실행 가능한 통찰로 변환시키는 능력에 대해 알아보세요.
June 24, 2025
더 읽기
산업 솔루션
Solidigm과 함께 AI 스토리지 분야의 전문가가 참여하는 AI 인프라 현장의 날 행사에서 동급 최강의 솔루션, 역사, 경험, 파트너십에 대해 자세히 알아보세요.
June 17, 2025
더 읽기
산업 솔루션
다중 서버, GPU, 엣지 장치 간 원활한 데이터 공유를 지원하는 대용량 SSD로 최적화된 NAS가 협업적이고 반복적인 특성을 갖는 AI 워크플로우에 얼마나 적합한지 알아보세요.
June 3, 2025
더 읽기
기술 인사이트
현재 시중에서 가장 밀도가 높은 QLC NAND에서 포장이 SSD 폼 팩터의 다이 적층에 어떤 근본적인 역할을 하는지 알아보세요.
May 26, 2025
더 읽기
산업 솔루션
Antillion이 Solidigm SSD의 도움으로 어떻게 공간, 무게, 이동성의 제약을 넘어 가장 작고 휴대성이 뛰어난 폼 팩터로 고성능 엣지 솔루션을 설계하는지 알아보세요.
May 20, 2025
더 읽기
산업 솔루션
VAST 데이터, DUG, Solidigm이 스토리지와 컴퓨팅 인프라에 엄청난 스트레스를 주는 RNA 염기서열분석 시 데이터 사용 문제를 어떻게 해결하는지 알아보십시오.
May 13, 2025
더 읽기
기술 인사이트
기업의 트랜잭션 응답성, 서비스 확장성, 데이터 주권을 지원하기 위해 엔터프라이즈 컴퓨팅이 엣지 처리로 이동하고 있는 이유를 알아보십시오.
May 6, 2025
더 읽기
산업 솔루션
Ocient의 새로운 연구에서 SSD가 생애주기 동안 어떻게 탄소 발자국을 줄여 AI 애플리케이션의 지속 가능성을 높이는지 알아보십시오.
April 29, 2025
더 읽기
산업 솔루션
Cloudflare의 Rita Kozlov가 Solidigm 및 TechArena와 함께하는 이 팟캐스트에서 AI, 개인정보보호, 지속가능한 컴퓨팅에 대해 논의하는 것을 들어보세요.
April 15, 2025
더 읽기
기술 인사이트
NASA의 Laura Carriere가 Jeniece Wnorowski와 함께 기후 시뮬레이션을 위해 위성으로부터 수집한 방대한 양의 데이터를 저장하고 사용하는 방법에 대해 나누는 이야기를 들어보세요.
April 8, 2025
더 읽기
산업 솔루션
엔터프라이즈 스토리지 서버에 핫스왑이 가능하고 팬이 필요 없는 냉각 기능을 제공하는 완전히 새로운 Solidigm의 완전 수냉식 SSD 솔루션에 대해 알아보세요.
April 1, 2025
더 읽기
산업 솔루션
Solidigm과 GIGABYTE가 최첨단 스토리지와 시스템 통합을 통해 AI 학습 성능을 어떻게 재정의하고 있는지 알아보십시오. 고성능 대용량 SSD를 활용하여 데이터 병목 현상을 최소화하는 협업 솔루션에 대해 알아보십시오.
March 18, 2025
더 읽기
산업 솔루션
Solidigm S3 Fuse 솔루션이 오브젝트 스토리지를 사용하여 어떻게 AI 학습과 추론 프레임워크를 오픈 소스 프로젝트와 통합하고 S3 스토리지를 파일 시스템과 연결하는지 알아보십시오.
March 13, 2025
더 읽기
고객 사례
Solidigm SSD가 가축 생산 효율성과 건강을 개선하기 위해 AI를 사용하여 가축 농가의 지능적인 사육을 지원하는 방법을 알아보십시오.
March 4, 2025
더 읽기
기술 인사이트
Solidigm이 대용량 드라이브로 네트워크 제한을 극복하여 SSD의 일관성과 우수성을 통해 고객을 확보하는 방법을 알아보십시오.
February 25, 2025
더 읽기
산업 솔루션
Moor Insights & Strategy 백서에서 데이터 센터가 성능 및 지속 가능성 문제를 해결하는 방법을 알아보십시오. Solidigm SSD를 사용하면 성능을 저하시키지 않고 어떻게 전력을 절약할 수 있는지 알아보십시오.
February 11, 2025
더 읽기
산업 솔루션
Alluxio와 Solidigm이 스토리지 대역폭 소비를 줄이기 위해 AI 워크로드를 위한 고급 캐시 솔루션을 만든 방법을 알아보십시오.
January 21, 2025
더 읽기
기술 인사이트
이 Signal65 Lab 백서를 통해 Solidigm QLC SSD가 AI 데이터 센터의 전력 소비량 측면에서 TLC SSD 및 하이브리드 스토리지 솔루션과 어떻게 비교되는지 확인할 수 있습니다.
January 14, 2025
더 읽기
산업 솔루션
Solidigm의 고밀도 QLC SSD가 엣지 데이터 스토리지 솔루션으로 TV와 영화 산업을 어떻게 변모시키고 있는지 알아보십시오.
December 31, 2024
더 읽기
산업 솔루션
데이터가 세상에 어떤 영향을 미치는지 알아보십시오. 특히 Solidigm 122TB QLC 드라이브가 HPC 클러스터 성능을 어떻게 변모시키는지 알아보십시오.
December 24, 2024
더 읽기
제품 인사이트
AI 데이터 스토리지 과제가 어떻게 Solidigm의 122TB SSD로 해결되어 데이터 센터부터 에지까지 실제 고객 솔루션을 제공하고 있는지 알아보세요.
December 19, 2024
더 읽기
기술 인사이트
AI와 함께 하이브리드 스토리지 어레이를 사용하고 있다면, 올플래시 스토리지가 어떻게 데이터 배치를 최적화하고 TCO까지 절감할 수 있는지 알아보십시오.
December 17, 2024
더 읽기
산업 솔루션
야생동물 보호의 미래가 Solidigm의 61.44TB SSD와 같은 고성능 데이터 스토리지에 의존하는 이유를 알아보십시오.
December 3, 2024
더 읽기
기술 인사이트
초고밀도 데이터 저장 기술이 데이터 센터의 에너지 효율을 높이고 비용과 전력 소비를 줄이는 방법에 대해 알아보십시오.
November 26, 2024
더 읽기
기술 인사이트
Solidigm 엔지니어들이 어떻게 수십 년간의 성과를 활용하여 122TB D5-P5336 SSD를 출시했는지 알아보세요.
November 12, 2024
더 읽기
제품 인사이트
AI를 이용한 더 빠르고 정확한 진단으로 의료진과 환자에게 새로운 희망과 가능성을 제공하는 데 있어 Solidigm SSD가 어떻게 기여하는지 알아보세요.
September 16, 2024
더 읽기
비디오
AI 시대를 위해 최적화된 효율적인 대용량 SSD로 대규모 AI 성능과 효율성을 구현하여 Solidigm이 어떻게 AI 준비, 개발 및 배포를 가속화하고 있는지 확인해 보십시오.
August 27, 2024
더 읽기
비디오
이 두 비디오에서 솔리다임과 Supermicro가 AI 데이터 파이프라인에 대한 고객 요구 사항을 충족하기 위한 AI 스토리지의 역할을 개선하기 위해 어떻게 협력하는지 알아보십시오.
April 9, 2024
더 읽기
특집 기사
솔리다임 SSD가 어떻게 대용량 데이터를 위한 에지 스토리지 솔루션으로 천체 사진의 발전을 이끄는지 알아보십시오.
March 26, 2024
더 읽기
비디오
솔리다임 및 VAST Data 비디오 토론에서 스토리지가 AI 워크로드 성능의 핵심인 이유와 데이터 파이프라인의 각 단계에서 스토리지가 수행하는 역할을 알아보십시오.
March 12, 2024
더 읽기
백서
데이터 수집, 개발 및 배포를 위한 AI 기술 발전에서 솔리다임 SSD가 어떤 역할을 하는지 알아보십시오.
February 13, 2024
더 읽기
고객 사례
Learn how Kingsoft Cloud partnered with Solidigm SSDs to design innovative object storage for AI workloads in this customer success story.
January 30, 2024
더 읽기
특집 기사
Storage Review의 Jordan Ranous가 작성한 심층 리뷰에서 Dell PowerEdge의 '견고한 에지' 서버가 혹독한 환경에서 Solidigm SSD를 어떻게 사용했는지 알아보십시오,
January 23, 2024
더 읽기
제품 인사이트
QLC SSD의 이점을 활용하여 데이터를 에지와 코어에서 구동하는 데이터 소비의 새로운 사용 사례를 알아보십시오.
January 16, 2024
더 읽기
제품 인사이트
Storage Review가 솔리다임 SSD의 CDN 응답성을 검사하여 Varnish Software의 MSE(Massive Storage Engine)에서 고밀도 QLC 스토리지의 효율성을 보여주는 방법을 알아보십시오.
January 9, 2024
더 읽기
제품 인사이트
솔리다임 팀원이 등장하는 에지에서 고밀도 스토리지의 가치를 간략하게 설명하는 3개의 비디오를 시청하십시오.
December 5, 2023
더 읽기
제품 인사이트
Gestalt IT의 Storage Field Day에서 솔리다임이 발표한 바와 같이 QLC SSD가 오늘날의 읽기 집약적인 워크로드의 요구 사항을 어떻게 충족하는지 알아보십시오.
November 28, 2023
더 읽기
제품 인사이트
2023년 OCP 서밋에서 솔리다임 엔지니어들과 함께 TechArena가 후원하는 이 팟캐스트에서 AI가 스토리지 업계를 어떻게 변화시키고 있는지 알아보십시오.
November 21, 2023
더 읽기
고객 사례
이 고객 스토리에서 솔리다임과 Cheetah RAID AI가 QLC SSD를 통해 자율 주행 차량, 미디어 및 엔터테인먼트에서 데이터 저장과 전송을 위한 데이터 병목 현상을 어떻게 극복했는지 살펴보십시오.
October 31, 2023
더 읽기
비디오
제품 마케팅 선임 매니저인 Yuyang Sun이 주최하는 이 교육 비디오에서 솔리다임 D5-P5336 QLC SSD에 대한 모든 것을 알아보십시오.
October 29, 2023
더 읽기
제품 인사이트
Learn how the future of data storage includes Computational Storage, which will create a better ecosystem as the market and technologies move forward.
October 24, 2023
더 읽기
제품 인사이트
QLC는 메인스트림 워크로드를 위한 준비가 완료되었습니다. 데이터 센터와 기업에서 이미 이 기술을 어떻게 활용하고 있는지 알아보십시오.
October 10, 2023
더 읽기
제품 인사이트
LLM 및 AI와 같이 막대한 양의 데이터를 사용하는 애플리케이션을 위해 EDSFF SSD가 어떻게 클라우드 스토리지 및 컴퓨팅의 성능을 극대화할 수 있는지 알아보십시오.
September 7, 2023
더 읽기
제품 인사이트
데이터 스토리지 수요의 증가가 어떻게 SATA에서 NVMe로의 전환을 가속화하여 성능을 개선하고 TCO를 절감하는지 알아보십시오. 이제 변화할 준비가 되셨습니까?
September 5, 2023
더 읽기
제품 인사이트
솔리다임 D5 시리즈 SSD가 에지 스토리지 요구 사항에 맞는 최고의 성능과 가치를 제공하는 자세한 방법.
August 29, 2023
더 읽기
제품 인사이트
Storage Review가 솔리다임 QLC SSD를 사용하여 Google Cloud의 2022년 기록을 3분의 1에 해당하는 54일 만에 갱신하고 100조 자리의 원주율을 계산한 방법을 알아보십시오.
August 25, 2023
더 읽기
제품 인사이트
새로운 솔리다임 D5-P5336이 벤치마크 테스트에서 어떤 성능을 보였는지 확인하고, 이 획기적인 60TB SSD가 어떻게 차세대 데이터 센터 스토리지 솔루션이 될 수 있는지 알아보십시오.
August 22, 2023
더 읽기
기술 개요
Solidigm이 어떻게 Intel, StarWind, 그 외 업계 파트너 및 스토리지 성능 개발 키트(SPDK) 커뮤니티와 협력하여 더 적은 TCO로 우수한 성능을 제공하는 CSAL 참조 스토리지 플랫폼을 개발했는지 알아보십시오.
August 15, 2023
더 읽기
제품 인사이트
Dell PERC 12의 솔리다임 SSD가 어떻게 성능 병목 현상을 완화하여 RAID 카드 구성의 결과를 최적화하는지 알아보십시오.
August 15, 2023
더 읽기
제품 인사이트
CSAL이 호스트 측의 FTL를 통해 모든 쓰기 워크로드를 순차 쓰기 워크로드로 전환하여 고밀도 낸드 플래시 미디어의 가치를 실현한 방법을 알아보십시오.
August 15, 2023
더 읽기
제품 인사이트
Gestalt IT의 Stephen Foskett이 엣지 환경에서 고급 솔리드 스테이트 드라이브의 가치에 대해 논의하고 솔리다임 D5-P5430에 대해 이야기합니다.
August 9, 2023
더 읽기
백서
고객은 빠르면서도 비싸지 않은 솔루션을 원합니다. 안타깝게도 기존의 스토리지 솔루션은 선택을 강요합니다. 많은 조직들은 비즈니스 상황에 따라 다양한 데이터 및 애플리케이션의 요건을 충족하기 위해 여러 스토리지 시스템을 도입합니다.
June 26, 2023
더 읽기
기술 개요
D5-P5336은 데이터 센터용 4세대 QLC SSD로, 읽기와 데이터 집약적 워크로드에 최적화된 업계 최고 수준의 성능과 최대 61.44TB의 대용량 스토리지를 제공합니다.
June 25, 2023
더 읽기
기술 개요
QLC 3D NAND SSD를 사용하면 일반적인 읽기 중심의 워크로드에 필요한 안정성과 저지연 성능을 제공하면서 통합을 통해 스토리지 비용을 절감하는 데 어떻게 도움이 되는지 확인해 보십시오.
June 20, 2023
더 읽기
백서
적절한 PCIe Gen 4 SSD는 데이터 증가, 높아진 사용자 기대치 및 예산 문제 사이에서 균형을 유지합니다. 사용 사례에 적합한 제품을 선택하는 방법에 대해 알아보십시오.
June 19, 2023
더 읽기
비디오
솔리다임의 Alexey Rogachkov가 CloudFest 2023 기조 연설에서 발표한 클라우드 스토리지를 개선하는 세 가지 방법을 이 비디오에서 확인해 보십시오.
June 5, 2023
더 읽기
인포그래픽
솔리다임의 인포그래픽을 통해 귀하의 PC에 가장 적합한 SSD를 선택하는 방법을 쉽고 빠르게 알아보십시오.
May 30, 2023
더 읽기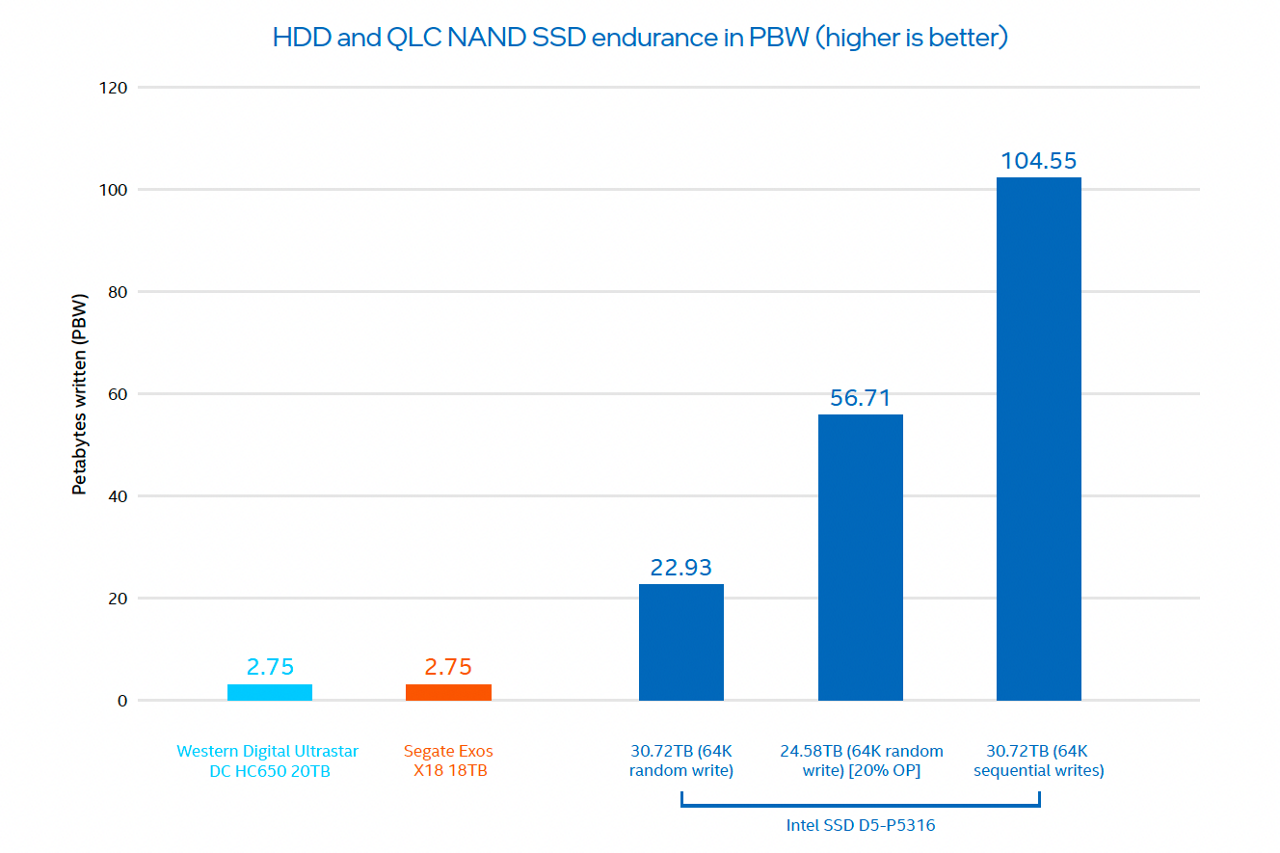
기술 개요
기술 개요에서 솔리다임 QLC 3D NAND SSD가 어떻게 HDD를 능가하고 하이브리드 어레이 또는 모든 TLC NAND SSD 어레이에 비해 상당한 용량 및 비용 이점을 제공하는지 알아보십시오.
May 29, 2023
더 읽기
기술 개요
워크로드 개요에서 QLC SSD가 어떻게 읽기 성능에 최적화된 고밀도 PCIe NAND 기술로 방대한 데이터 집합에 대한 액세스를 가속화할 수 있는지 알아보십시오.
May 28, 2023
더 읽기
백서
Ace Stryker와 함께 Solidigm Synergy 소프트웨어로 어떻게 SSD의 잠재력을 최대한 발휘할 수 있을지 알아보세요.
May 20, 2023
더 읽기
기술 개요
데이터가 빠르게 증가하면서 데이터 센터와 스토리지 확장성의 한계를 시험하고 있습니다. AI, ML, CDN(content-delivery networks), 오브젝트 기반 스토리지, 데이터 분석과 같은 최신 데이터 집약적 워크로드를 처리하려면 방대한 양의 데이터를 효율적으로 저장하고 빠르게 액세스할 수 있어야 합니다. 기존에는 성능과 용량 중 어느 쪽에 비중을 더 둘 것인지 고민했습니다. 애플리케이션이 성능을 요구할 경우 SSD를, 용량을 우선으로 하는 경우
May 14, 2023
더 읽기
기술 개요
데이터가 빠르게 증가하면서 데이터 센터와 스토리지 확장성의 한계를 시험하고 있습니다. AI, ML, CDN(content-delivery networks), 오브젝트 기반 스토리지, 데이터 분석과 같은 최신 데이터 집약적 워크로드를 처리하려면 방대한 양의 데이터를 효율적으로 저장하고 빠르게 액세스할 수 있어야 합니다. 기존에는 성능과 용량 중 어느 쪽에 비중을 더 둘 것인지 고민했습니다. 애플리케이션이 성
May 14, 2023
더 읽기
비디오
오늘날 배포되는 대규모 워크로드로 인해 최상의 데이터 스토리지 옵션을 선택하는 것이 어려울 수 있습니다. 많은 스토리지 설계자가 최악의 시나리오에 대비하여 인프라를 설계하지만 오늘날 워크로드는 메인스트림 애플리케이션이 점차 데이터 집약적으로 바뀌면서 변화하고 있습니다.
May 14, 2023
더 읽기
제품 인사이트
오늘날 세계는 점차 더 방대해지는 데이터를 생성하고 소비할 수 있는 무한한 능력을 갖고 있는 것 같습니다. 이런 데이터 쓰나미는 읽기 집약적인 워크로드의 증가 가속화와 함께 SSD
April 23, 2023
더 읽기
제품 인사이트
적절한 크기의 SSD를 선택하여 성능 저하 없이 비용을 절감할 수 있는 방법을 알아보십시오. 읽기 집약적 워크로드에 집중하여 SSD 사용을 변화시킬 수 있는 방법을 알아보십시오.
April 23, 2023
더 읽기
고객 사례
자율 주행 차량 안전을 위한 여러 카메라 및 센서의 테스트 주행 데이터용 스토리지를 관리하기 위해 InoNet과 Solidigm이 어떻게 협력했는지 알아보십시오.
April 8, 2023
더 읽기
제품 인사이트
스토리지 옵션을 탐색하고 TCO를 비교 중인 클라우드 서비스 제공업체라면, SSD가 어떻게 HDD보다 총 소유 비용이 낮고 지속가능성이 높은 스토리지를 제공하는지 알아보세요.
March 29, 2023
더 읽기
기술 인사이트
SSD, 클라우드 서비스, 외부 스토리지 드라이브와 같은 보안 백업 옵션이 어떻게 데이터를 보호하는지 알아보십시오.
March 25, 2023
더 읽기
비디오
업계 최고의 제품과 기술 포트폴리오를 갖춘 Solidigm은 데이터 스토리지에 대한 고유한 관점을 지니고 있습니다. 효율적인 스토리지를 앞당기기 위한 초고밀도 SSD에 대한 비전과 회사의 발전 계획 개요를 알아보도록 하겠습니다. 구체적으로 Solidigm의
November 16, 2022
더 읽기
제품 인사이트
데이터 풀을 페타바이트 단위로 확장하려는 고객이 활용할 수 있는, 비구조적인 데이터세트를 고속 PCIe SSD로 처리하는 옵션은 많지 않습니다. 솔리다임은 데이터 센터 고객의 요구 사항을 보다 잘 충족하는 솔루션을 제공하기 위한 고유한 제품 포트폴리오를 갖추고 있습니다 당사는 플로팅 게이트 및 충전 트랩 제작 기술을 기반으로
November 15, 2022
더 읽기
제품 인사이트
기존 4코너의 스토리지 성능 벤치마킹은 오늘날의 최신 클라우드 및 엔터프라이즈 워크로드 IO의 대부분을 정확하게 나타내지 않습니다. 당사의 드라이브는 보다 대표적인 쓰기
October 17, 2022
더 읽기
인포그래픽
기존 4코너의 스토리지 성능 벤치마킹은 오늘날의 최신 클라우드 및 엔터프라이즈 워크로드 IO의 대부분을 정확하게 나타내지 않습니다. 당사의 드라이브는 보다 대표적인 쓰기 압력, 혼합된 R/W,
October 15, 2022
더 읽기
기술 인사이트
SSD와 HDD 메모리 중 어디에 투자해야 하는지 궁금하십니까? 솔리다임 가이드를 읽고 귀하에게 적합한 제품이 무엇인지 확인해 보십시오.
September 11, 2022
더 읽기
고객 사례
금융 서비스 회사는 분산형 소프트웨어 정의 스토리지를 사용하여 총 소유 비용을 낮출 수 있습니다.
September 10, 2022
더 읽기
고객 사례
솔리다임의 SSD는 Kingsoft Cloud가 하이브리드 클라우드 스토리지 제품을 만들어 기업의 디지털 혁신을 가속화할 수 있도록 지원합니다. 자세한 방법을 알아보세요.
August 29, 2022
더 읽기
고객 사례
DUG Technology는 하드 디스크 드라이브에서 인텔® Optane™ 기술 기반의 페타바이트급 플래시 스토리지로 전환했습니다. 스위치와 그 이점을 자세히 살펴보십시오.
August 13, 2022
더 읽기






